When designing a website, you need to make sure that users can find the information they are seeking fast and easily.
One way to do this is to add search capabilities to the site. Two search features you can add to your site are a Static index or Site map and a search engine.
Static index or Site map
This type of search feature is simply a Web page within a site with hyperlinks to the different categories of the website.
This type of searching is not interactive, users do not have the option of typing in a keyword or phrase.
Instead, users are given a list of content to choose from and must click links until they locate the information.
This is a test to see if the background will change.
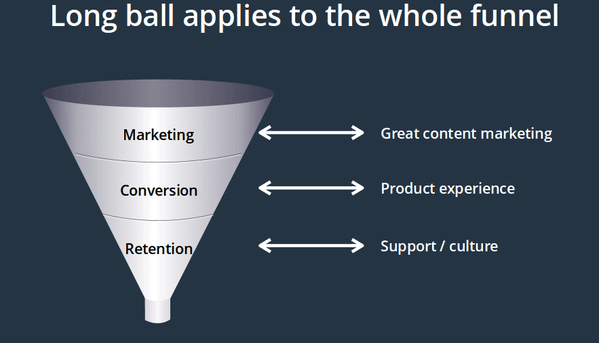
Marketing consisting of the three components 1) Marketing, 2) Conversion, 3) Retention
Search Engine Services
Search engines provide a variety of services, including:
Web Search: Search engines allow users to search the internet for information by entering keywords or phrases into a search box. The search engine then retrieves and ranks relevant web pages based on various factors, such as relevance, popularity, and authority.
Image Search: Search engines also allow users to search for images by entering keywords or phrases. The search engine then retrieves and ranks relevant images based on factors such as relevance, popularity, and resolution.
Video Search: Search engines also allow users to search for videos by entering keywords or phrases. The search engine then retrieves and ranks relevant videos based on factors such as relevance, popularity, and view count.
News Search: Search engines also allow users to search for news articles by entering keywords or phrases. The search engine then retrieves and ranks relevant news articles based on factors such as relevance, timeliness, and authority.
Map Search: Search engines also allow users to search for locations and directions by entering addresses or place names. The search engine then displays a map with the relevant location and provides directions if requested.
Product Search: Search engines also allow users to search for products by entering keywords or phrases. The search engine then retrieves and ranks relevant products based on factors such as relevance, price, and popularity.
Scholarly Search: Search engines also offer specialized search services for scholarly articles, such as Google Scholar. These services allow users to search for academic papers, theses, and other scholarly publications.
Translation: Search engines also offer translation services. Users can enter text in one language and the search engine will translate it into another language.
Weather: Search engines also provide weather forecasts for different locations. Users can enter a location and the search engine will display the current weather conditions and forecast.
Currency Conversion: Search engines also offer currency conversion services. Users can enter an amount in one currency and the search engine will convert it to another currency.
Search engines provide an interactive way for users to find information on a particular website.
They are considered secondary navigational devices and are most useful when you know what you are looking for. This is called known item searching. website developers can build a search engine into their site. Users can then type in keywords for faster results.
An example of a website that allows users to do keyword searches within their site is Amazon.
An effective search engine is essential for sites rich with content, such as descriptions of many products or archives of many files.
A well-designed search engine is a powerful navigational tool for an experienced or a novice Web user.
In the next lesson, more about browser and cross-platform compatibility issues in Web design will be discussed.
The following section explores a variety of sites with search engines.
Using Search Engines
Log on to one of the following websites listed below and experiment with different search queries to examine the results.
When you are exploring these sites and putting their search engines to the test, think about the following.
How do the search engines differ in function and feel?
What design elements make one site's search engine easier to use than that of another site?
For example, was it obvious where to enter keywords?
Did you get lost? If so, at what point in the search?
Search based on a user query (sometimes called ad hoc search because the range of possible queries is huge and not prespecified) is not the only text-based task that is studied in information retrieval. Other tasks include filtering, classification, and question answering. Filtering or tracking involves detecting stories of interest based on a person'sinterests and providing an alert using email or some other mechanism.
Classification or categorization uses a defined set of labels or classes (such as the categories listed in the Yahoo! Directory) and automatically assigns those labels to documents.
Question answering is similar to search but is aimed at more specific questions, such as
What is the height of Mt. Everest?.
The goal of question answering is to return a specific answer found in the text, rather than a list of documents.
Information Retrieval
Information retrieval researchers have focused on a few key issues that remain, which are just as important in the era of commercial web search engines. which work with billions of web pages. These tests were done in the 1960s on "document collections" containing about 1.5 megabytes of text. One of these issues is relevance, which is a fundamental concept in information retrieval.
Loosely speaking, a relevant document contains the information that a person was looking for when she submitted a query to the search engine. Although this sounds simple, there are many factors that go into a person's decision as to whether a particular document is relevant. These factors must be taken into account when designing algorithms for comparing text and ranking documents. Simply comparing the text of a query with the text of a document and looking for an exact match, as might be done in a database system or using the grep utility in Unix, produces very poor results in terms of relevance.
One obvious reason for this is that language can be used to express the same concepts in many different ways, often with very different words.
This is referred to as the vocabulary mismatch problem in information retrieval. It is also important to distinguish between topical relevance and user relevance.
A text document is topically relevant to a query if it is on the same topic. For example, a news story about a tornado in Kansas would be topically relevant to the query 'severe weather events'. The person who asked the question (often called the user) may not consider the story relevant, however, if she has seen that story before, or if the story is five years old, or if the story is in Chinese from a Chinese news agency.
User relevance takes these additional features of the story into account.
Within the context of information retrieval, a "relevant document" is one that satisfies the information need of a user. This definition is subjective and depends on several factors:
User Intent: What information is the user looking for? Are they seeking factual information, trying to understand a concept, or looking for specific instructions? Different intents require different types of documents to be considered relevant.
Content Match: How well does the document's content address the user's query terms and concepts? This can involve keyword matching, semantic understanding, and consideration of synonyms and related terms.
Context: What is the surrounding context of the search? Is the user looking for recent news articles, academic papers, product reviews, or something else? Understanding the context helps identify documents relevant to the specific situation.
Additional factors: Beyond content and keywords, relevance can be influenced by factors like document format (e.g., article vs. book), author credibility, source reputation, and timeliness (for recent information).
Therefore, a relevant document is not necessarily the one that perfectly matches the query keywords. It's the one that best addresses the user's information need based on the factors mentioned above.
Here are some additional points to consider:
Relevance is often graded rather than binary. Some documents might be highly relevant, while others are less so, but still useful depending on the user's specific needs.
Information retrieval systems use various techniques to assess relevance, including statistical algorithms, machine learning models, and knowledge graphs.
The definition of "relevant" can evolve over time as user needs and search technologies change.