| Lesson 3 | Search Engines |
| Objective | A Search Engine creates and maintains its Database of Sites |
How Search Engines create Database Index
Search engines create database indexes to optimize the search process and speed up retrieval of results. The indexing process involves the following steps:
Once the index is created, the search engine can quickly retrieve and display the relevant results for a given search query, based on the indexed information. The index is typically stored in a database, which is optimized for fast retrieval and search performance.
- Crawling: The search engine crawls the web and gathers information about the content of web pages, such as keywords, metadata, links, and other relevant data.
- Parsing: The search engine parses the content of the web pages and extracts the relevant information, such as text content, images, and other media.
- Tokenization: The search engine breaks down the extracted information into smaller units, such as words or phrases, and assigns each unit a unique identifier.
- Stemming: The search engine applies stemming algorithms to the tokens to normalize them and reduce them to their root form. This allows the search engine to match variations of the same word, such as "run," "running," and "ran."
- Stop word removal: The search engine removes common stop words, such as "the," "and," and "a," which do not add meaning to the search query.
- Indexing: The search engine creates an index of the tokens and their corresponding web pages. The index contains a list of the tokens, along with their frequency and location in the web pages.
- Ranking: The search engine applies a ranking algorithm to the indexed pages to determine the relevance and order of the results for a given search query.
Once the index is created, the search engine can quickly retrieve and display the relevant results for a given search query, based on the indexed information. The index is typically stored in a database, which is optimized for fast retrieval and search performance.
Maintain Database of Sites
In the previous module, we discussed the central characteristic of search engines that makes them different from directories.
Search engine data is compiled by computer programs called robots or spiders that search the Web (and some search services search other areas of the Internet, as well) for documents, index them, and then store the results in a database.
The following SlideShow shows you the sequence of operations:
The following SlideShow shows you the sequence of operations:

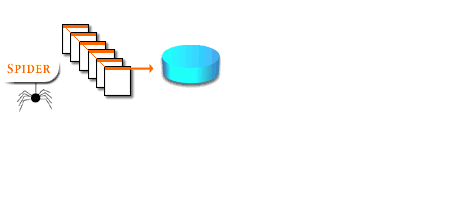
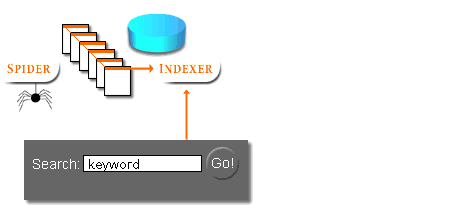
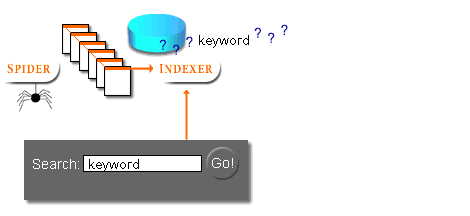
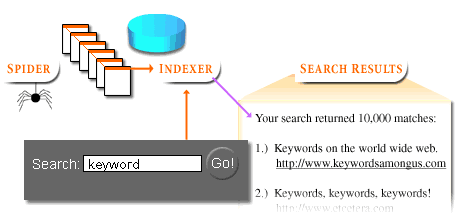
- Automated robot or spider programs read information day after day from websites
- Information is stored and indexed in the search service's database
- Compose a search query from keywords and symbols
- The search engine searches the service's database with its software
- Matches or hits are then assembled into a list of search engine result Sets
Search Engine Operations
Robots and Spiders
Robots are also called spiders or crawlers.
Most people use the terms Web index, search engine, and search service interchangeably to refer to a site or service that allows you to define a search query that will retrieve specific information online. IN 2018 there are 4 primary search engines. Google, Bing, Yahoo, duckduckgo.com. The search engines listed below existed during the dotcom era and are no longer being used.
When people refer to sites such as AltaVista or Excite as search engines, they are not exactly correct. These sites are actually commercial services that provide you with an interface and a search engine (the software that actually searches the database) with which to search a database of Web documents (or portions of Web documents) Each commercial service has its own search engine searching software and indexing robot. The combination of a robot-generated database and a search engine is also referred to as a Web index.
Although it may seem that a search engine will always overpower a directory through the sheer size of its automated database, there are a couple of limitations of individual search engines that you should know about, the percentage of all Web documents that are searched, overlap between search engine services, and how they deal with synonyms and homonyms.
Most people use the terms Web index, search engine, and search service interchangeably to refer to a site or service that allows you to define a search query that will retrieve specific information online. IN 2018 there are 4 primary search engines. Google, Bing, Yahoo, duckduckgo.com. The search engines listed below existed during the dotcom era and are no longer being used.
When people refer to sites such as AltaVista or Excite as search engines, they are not exactly correct. These sites are actually commercial services that provide you with an interface and a search engine (the software that actually searches the database) with which to search a database of Web documents (or portions of Web documents) Each commercial service has its own search engine searching software and indexing robot. The combination of a robot-generated database and a search engine is also referred to as a Web index.
Although it may seem that a search engine will always overpower a directory through the sheer size of its automated database, there are a couple of limitations of individual search engines that you should know about, the percentage of all Web documents that are searched, overlap between search engine services, and how they deal with synonyms and homonyms.
As modern search engines evolved, they started to take into account the link profile of both a given page and its domain. They found out that the relationship between these two indicators was itself a very useful metric for ranking webpages.
Domain and Page Popularity
There are hundreds of factors that help engines decide how to rank a page. In general, those hundreds of factors can be broken into two categories: 1) relevance and 2) popularity or "authority". For the purposes of this demonstration you will need to completely ignore relevancy for a second.
Further, within the category of popularity, there are two primary types:
This is very clear if you start looking for patterns in search result pages. Have you ever noticed that popular domains like Wikipedia.org tend to rank for everything? This is because they have an enormous amount of domain popularity.
Question: But what about those competitors who outrank me for a specific term with a practically unknown domain?
This happens when they have an excess of page popularity.
- domain popularity and
- page popularity.
This is very clear if you start looking for patterns in search result pages. Have you ever noticed that popular domains like Wikipedia.org tend to rank for everything? This is because they have an enormous amount of domain popularity.
Question: But what about those competitors who outrank me for a specific term with a practically unknown domain?
This happens when they have an excess of page popularity.