Lesson 6
Search Engine Conclusion
Representative search sites in each of the major categories of information retrieval services has been discussed in this module. In this module, you have viewed some of the types of information stored in Web sites.
You have toured representative search sites in each of the major categories of information retrieval services. You have learned about some of the challenges to finding information on the Web, and you have seen typical search results pages from both a directory and a search engine.
You have toured representative search sites in each of the major categories of information retrieval services. You have learned about some of the challenges to finding information on the Web, and you have seen typical search results pages from both a directory and a search engine.
Now that you have finished this module, you should be able to:
- List various reasons people search the Internet
- Describe the different categories of information retrieval services
- Identify information on a search results page
- Explain why you need a search strategy
Eye Tracking Study
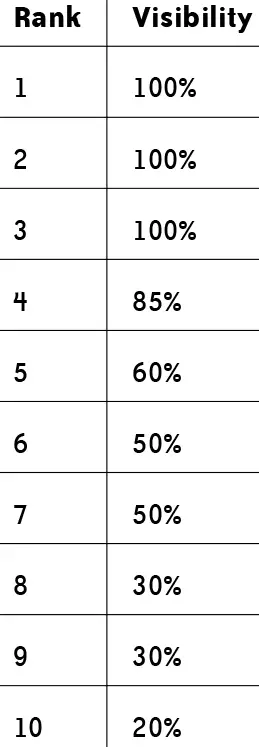
Further data from the Enquiro and Eyetools eye-tracking study shows which organic
results users notice when looking at a search results page (See Figure 2-6)
Similarly, Table 2-7 shows the percentage of users that look at each of the top paid results when viewing a search results page.
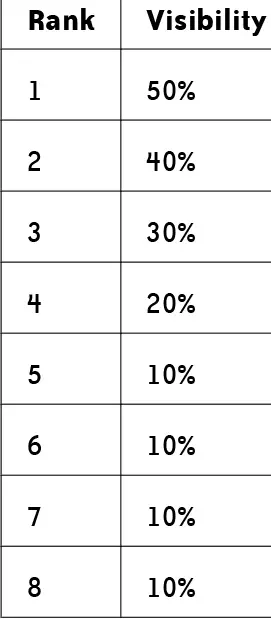
Notice this data shows that the visibility of a listing in the natural results is double or more (up to six times) of the visibility of the same position in the paid results.
For example, only 60% of users ever even notice the natural search result in position five, but the paid search results fare even worse, with only 10% of users noticing the result in the fifth position.
With the advent of Search, the visibility of the paid search results is even further reduced. Paid search advertisers will have increasing incentive to appear in the paid results that appear above the organic results, and advertisers that do not appear there are likely to receive even less traffic.
Module 2 - Glossary
This module introduced you to the following new terms:
- Directory: A database containing indexed Internet Web pages and returning lists of results which match queries.
Directories (also known as Catalogs) are normally compiled by hand, accept user submissions, and involve an editorial selection and breakdown into hierarchical categories. - Gopher: A menu-based text information searching tool that gives users access to various kinds of databases, such as FTP archives, and allows them to view information within them. Links are presented in hierarchical menus to the user. As users select options, they are moved to different Gopher servers on the Internet.
- Hypertext link: The underlined words that you click in one document that take you to another document, in the same Web site or in a different Web site. Each link has a URL (Uniform Resource Locator, or Web address) stored in it.
- Metasearch engine: A site offering a unified interface to multiple search services. Some provide a single search form that, once you have composed your query, will submit it to several different search engines. Others simply provide a list of different search engines and provide text fields with which to initiate a search through any specific engine.
- Robot: An automated program used by search services to follow and record Web links and index documents found on Web sites. The information is stored on a database for user searching. Also called "spiders."
- Search engine: A topical collection of information, references, and links to other Web sites, are also known as collection pages, compendium pages, and index pages. Typically, these pages are maintained by individuals; some are maintained by organizations.
- Search query: One or more words and optional operators used by search services to match against documents in a database. Words in a search query are also known as keywords.
- Subject page: A topical collection of information, references, and links to other Web sites, are also known as collection pages, compendium pages, and index pages. Typically, these pages are maintained by individuals; some are maintained by organizations.
- Usenet: Another section of the Internet that contains common areas of postings (or articles) and responses, broken down by categories, on a variety of subjects; Usenet is also referred to as "Newsgroups" or "Discussion groups."
- WAIS: Wide Area Information Server, a database on the Internet that contains indexes to documents that reside on the Internet. Using the Z39.50 query language, text files can be searched based on keywords. A directory of WAIS servers and sources is available from Thinking Machines Corporation, Cambridge, MA.
The next module will discuss the workings of directories and search engines in more detail.
You will make some simple searches and compare the results of searches in similar and different categories of search sites.
You will make some simple searches and compare the results of searches in similar and different categories of search sites.
Internet Search Quiz
Click the Quiz link below to review some topics that we have covered in this module.
Internet Search Quiz
Internet Search Quiz